Task Definition¶
Our benchmark comprises two subtasks: Language Model Retrieval and Image Style Transfer Model Retrieval.
Subtask A: Pre-trained BERT Model Retrieval¶
Retrieve and rank the most appropriate pre-trained BERT models for specific text classification tasks based on their expected downstream F1 performance.
1. Problem Definition¶
The core objective is to map a given classification task to the most effective pre-trained model from a defined candidate pool.
- Input: Training and validation data for a given classification task (provided as text and label pairs).
- Output: A ranked list of candidate pre-trained BERT models, sorted in descending order based on their expected F1 Score on an unseen test set.
Participant Methodology
Participants may choose whether or not to actually fine-tune the candidate models on the provided training/validation sets to determine their rankings. However, the chosen methodology must be clearly stated in the participant's working notes/paper.
2. Dataset Information¶
In the context of this retrieval task, "queries" represent downstream tasks, and "retrieval targets" represent the pre-trained models.
Queries¶
Text classification tasks, represented by text/label pairs.
Task Criticality
Every task is additionally labeled with a criticality tier, which determines how much the model performance varies across the different candidate models for that specific task.
- Low Criticality
- Medium Criticality
- High Criticality
Retrieval Targets¶
A candidate pool of pre-trained BERT models.
Available Data Splits¶
- Characteristics: 100 distinct synthetic text classification tasks generated by LLMs.
- Available Data: Participants have full access to the training data, validation data, and test data (each with text/label pairs) for each task.
- Ground Truth: The F1 Score of every candidate BERT model (after fine-tuning using the training/validation set and evaluating on the test set) is provided, allowing participants to train their retrieval/ranking systems.
- Characteristics: 48 real-world classification tasks sourced from Hugging Face.
- Available Data: Participants only have access to the training and validation data (text/label pairs). The test data is hidden.
- Objective: For each test query, participants must submit a ranked list of candidate models based on their predicted F1 score on the hidden test data.
How the dataset was created
For each task, we fine-tuned every candidate model on the training set and used early stopping on the validation set when validation loss did not improve for 10 epochs.
Training setup
- Learning rate:
2e-5 - Weight decay:
0.01 - Optimizer:
AdamW - Maximum epochs:
1000 - Early-stopping patience:
10 - Batch size:
16
3. Evaluation¶
System submissions will be evaluated as a standard ranking task using graded relevance scores.
Evaluation Metric¶
Submissions will be evaluated using nDCG@1,3,5
Where the Discounted Cumulative Gain (\(\text{DCG}_k\)) is defined as:
Relevance Score Definition¶
The "relevance" of a retrieval target (model) for a given query (task) is calculated in two steps based on relative performance:
Step 1: Normalization
Calculate the relative_f1 score for each model by dividing its test F1 score by the highest test F1 score achieved among all candidate models for that specific task.
Step 2: Relevance Mapping
The relative_f1 score is then mapped to a relevance grade:
| Condition | Relevance Score |
|---|---|
| \(\text{relative_f1} \le 0.90\) | 0 (Not relevant) |
| \(0.90 < \text{relative_f1} \le 0.95\) | 1 (Marginally relevant) |
| \(0.95 < \text{relative_f1} \le 0.99\) | 2 (Relevant) |
| \(\text{relative_f1} > 0.99\) | 3 (Highly relevant) |
4. Submission¶
Participants can submit up to 5 runs, using TREC_EVAL format:
- topicID: query task ID
- Q0: fixed string (Q0)
- docID: model ID
- Rank: ranking position of the model (Higher is better)
- Score: predicted score for the model
- RunID: your run identifier
Example¶
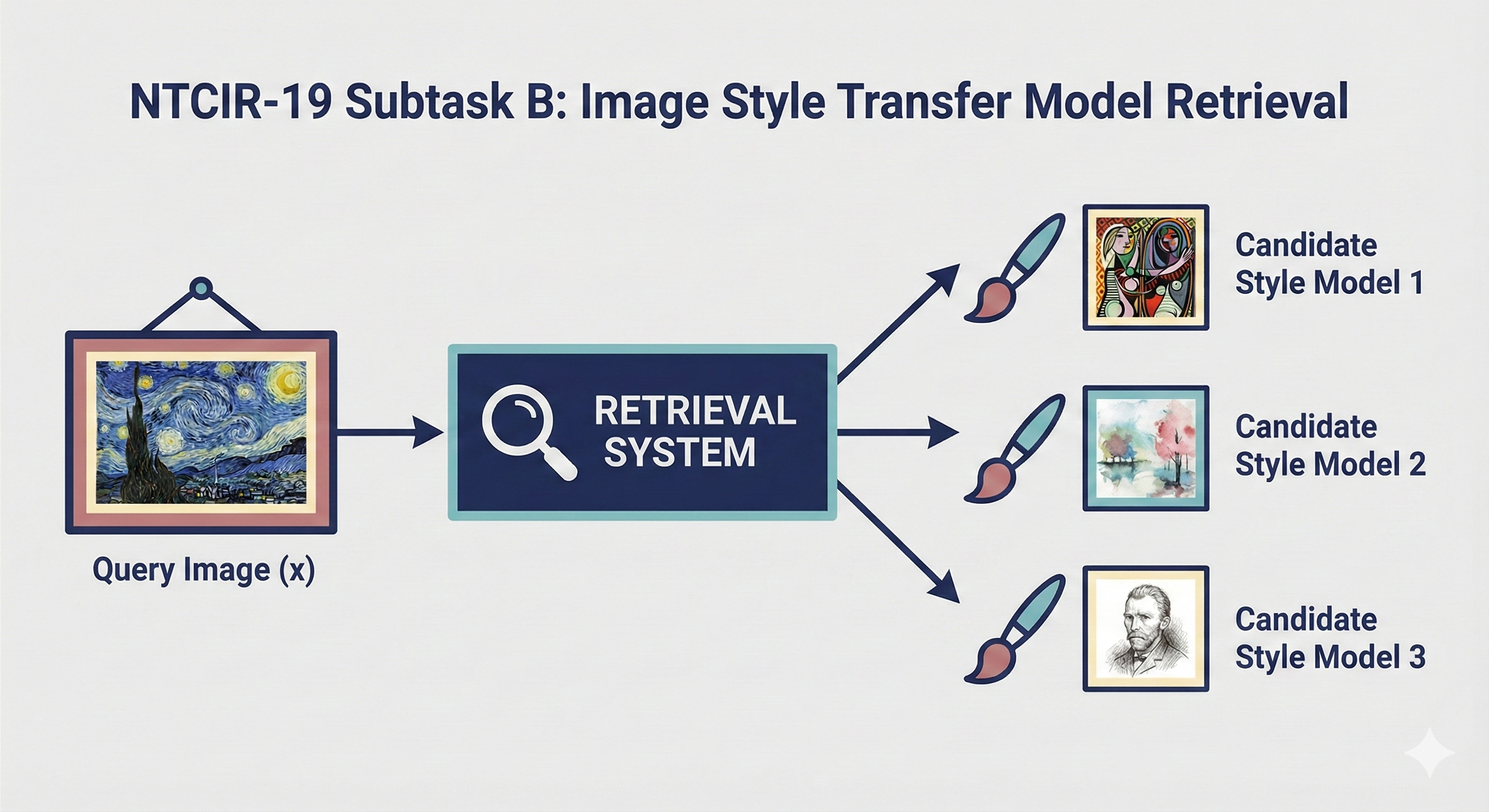
Subtask B: Image Style Transfer LoRA Model Retrieval¶
Retrieve and rank the most appropriate Image Style Transfer LoRA models for generating images that match the style of a given query image.
1. Problem Definition¶
The objective is to map a query image to the most suitable LoRA model from a candidate pool.
- Input: One query image with the desired style.
- Output: A ranked list of candidate Image Style Transfer LoRA models, sorted in descending order by their expected ability to generate images in the desired style.
2. Dataset Information¶
In this retrieval setting, "queries" are images with desired styles, and "retrieval targets" are Image Style Transfer LoRA models.
Queries¶
One desired-style image per query.
Retrieval Targets¶
A candidate pool of Image Style Transfer LoRA models.
Available Data Splits¶
- Size: 3740 images.
- Labels: Ground-truth LoRA model labels are provided.
- Relevance Setup: Each image has one positive model label; all other candidate models are treated as non-relevant (0).
- Size: 3825 images.
- Labels: Hidden.
How the dataset was created
We collected 89 public-domain portrait images from Unsplash as content images and 85 Image Style Transfer LoRA models (SDXL 1.5) from Civitai. We then generated images for every content-image and model pair.
To avoid leakage, training and test queries were split with no overlap in content images.
3. Evaluation¶
System submissions are evaluated as a ranking task using Mean Reciprocal Rank (MRR).
Relevance Score Definition¶
The relevance of a retrieval target (model) for a given query (image) is:
- 1 if that model was used to create the image.
- 0 otherwise.
Evaluation Metric¶
Submissions are evaluated using MRR:
where \(\mathrm{rank}_q\) is the rank position of the first relevant model for query \(q\).
4. Submission¶
Participants can submit up to 5 runs using the TREC_EVAL format:
Field definitions:
topicID: query image IDQ0: fixed token (Q0)docID: model IDRank: rank position (1 = highest)Score: predicted relevance scoreRunID: run identifier
Example: